What's the buzz around Synthetic Data?
I keep hearing the term “Synthetic Data” thrown around in the AI space. I wanted to slow down for a few minutes and dissect what it means, why it’s important, and where we go from here. Think of this as “Synthetic Data for Dummies” written by a dummy.
So, what is Synthetic Data?
I’m sure most people can guess the basic concept of Synthetic Data by breaking down the two words 🙂 but to be clear in this context: Synthetic Data is data generated by LLMs that is used to train (another LLM) on.
You can think about it this way: major LLMs like GPT, Llama, Gemini, etc. are all trained on data in the wild (hah) like the internet, research papers, whatever. Recently, researchers have found there are certain benefits to generating data with these larger models and using that dataset to train new models.
I should probably note here… that using GPT to generate datasets used to train new models is against OpenAI’s TOS (and likely against other organizations’ terms as well).
Why is it important?
The significance of Synthetic Data, from my basic understanding, can be broken down into three basic ideas: improving efficiency(cost), increased performance/accuracy, and better fine-tuning.
Efficiency
In the paper “Rephrasing the Web: A Recipe for Compute and Data-Efficient Language Modeling,” published in January, its authors proposed a new method coined as: Web Rephrase Augmented Pre-training (WRAP). They found that synthetically rephrasing data from the web into question and answer format significantly increased pre-training efficiency (thus reducing cost) by roughly 3x.
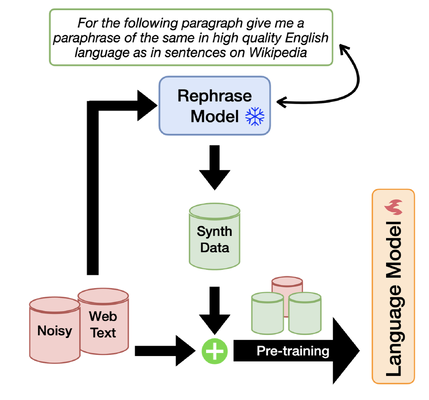
Essentially, Synthetic Data breaks down the barriers of cost ($) and time that surround training on real data.
Accuracy
The same researchers (and paper) found that the WRAP method allowed the model to become 10% better at predicting the next word in sentences it had never seen before and 2% better at answering questions it had never been trained on.
Moving forward, Synthetic Data has potential to allow models to provide accurate answers utilizing less data.
Fine-tuning
In the paper “Self-Rewarding Language Models,” researchers found that fine-tuning a language model by using self-created rewards (think of: synthetic rewards/feedback) allowed the model to significantly improve and outperform similar models.
In general, this proves that Synthetic Data in the form of rewards/feedback could be critical in autonomous self-improvement (without the need for human interaction).
What’s next?
The resources that informed my understanding were all published in 2024… Imagine a year from now - where we will be and what role Synthetic Data will play in AI’s advancements. Based on the research done here, Synthetic Data seems like a mechanism to reduce cost/time and improve accuracy in significant ways - which are critical advancements for those who are racing towards the finish line of AGI.
For someone like me, who’s more interested in the everyday utilization of language models than the creation of them, the practical use of Synthetic Data is probably minimal. It’s just a step towards our future and I think it’s important to maintain an awareness of what the smart folks writing these papers (and building the models) are up to 🙂
Reading/References: